WHAM:
Reconstructing World-grounded Humans with Accurate 3D Motion
CVPR 2024
Soyong Shin¹ Juyong Kim¹ Eni Halilaj¹ Michael J. Black²
¹ Carnegie Mellon University ² Max Planck Institute for Intelligent System
Abstract
The estimation of 3D human motion from video has progressed rapidly but current methods still have several key limitations. First, most methods estimate the human in camera coordinates. Second, prior work on estimating humans in global coordinates often assumes a flat ground plane and produces foot sliding. Third, the most accurate methods rely on computationally expensive optimization pipelines, limiting their use to offline applications. Finally, existing video-based methods are surprisingly less accurate than single-frame methods. We address these limitations with WHAM (World-grounded Humans with Accurate Motion), which accurately and efficiently reconstructs 3D human motion in a global coordinate system from video. WHAM learns to lift 2D keypoint sequences to 3D using motion capture data and fuses this with video features, integrating motion context and visual information. WHAM exploits camera angular velocity estimated from a SLAM method together with human motion to estimate the body's global trajectory. We combine this with a contact-aware trajectory refinement method that lets WHAM capture human motion in diverse conditions, such as climbing stairs. WHAM outperforms all existing 3D human motion recovery methods across multiple in-the-wild benchmarks. Code will be available for research purposes at https://wham.is.tue.mpg.de/.
Overview
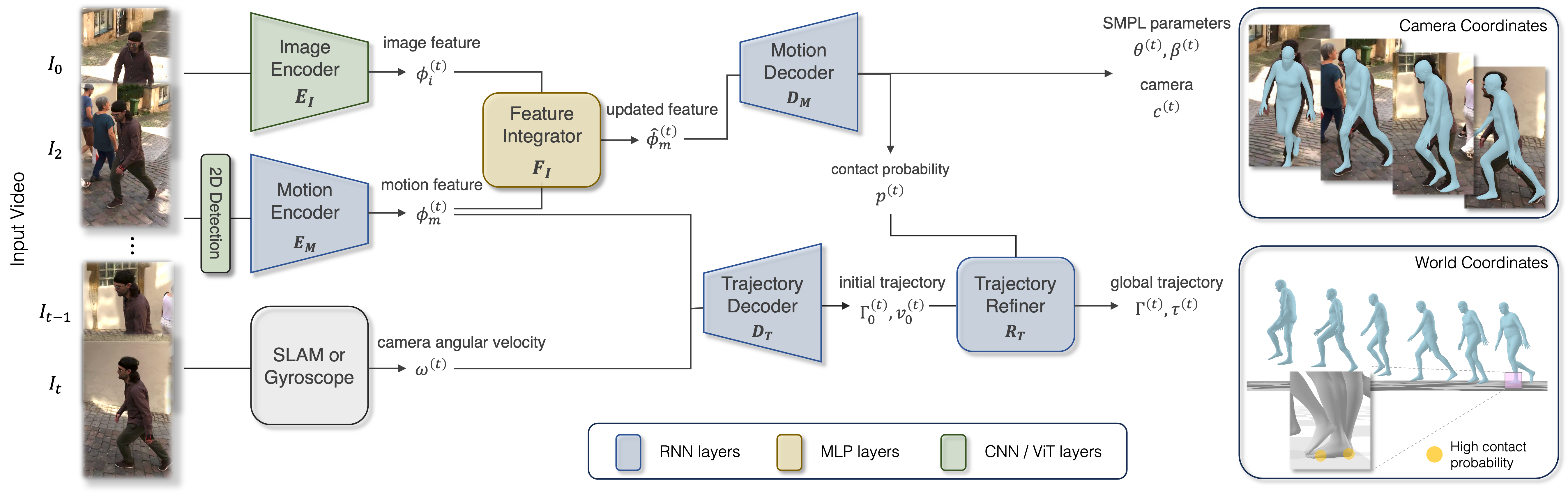
WHAM takes the sequence of 2D keypoints estimated by a pretrained detector and encodes it to the motion feature. WHAM then updates the motion feature using another sequence of image features extracted from the image encoder through the feature integrator. From the updated motion feature, the Local Motion Decoder estimates 3D motion in the camera coordinate system and foot-ground contact probability. The Trajectory Decoder takes the motion feature and camera angular velocity to initially estimate the global root orientation and egocentric velocity, which are then updated through the Trajectory Refiner using the foot-ground contact. The final output of WHAM is pixel-aligned 3D human motion with the 3D trajectory in the global coordinates.
Demos
Qualitative results on EMDB dataset.
Qualitative comparison with state-of-the-art methods.
Acknowledgment
We would like to sincerely appreciate Hongwei Yi and Silvia Zuffi for the discussion and proofreading. Part of this work was done when the first author was an intern at the Max Planck Institute for Intelligent System. This work was partially supported through an NSF CAREER Award (CBET 2145473) and a Chan-Zuckerberg Essential Open Source Software for Science Award.
Disclosure: MJB has received research gift funds from Adobe, Intel, Nvidia, Meta/Facebook, and Amazon. MJB has financial interests in Amazon, Datagen Technologies, and Meshcapade GmbH. While MJB is a consultant for Meshcapade, his research in this project was performed solely at, and funded solely by, the Max Planck Society.
Citation
@inproceedings{wham:cvpr:2024, title = {{WHAM}: Reconstructing World-grounded Humans with Accurate {3D} Motion}, author = {Shin, Soyong and Kim, Juyong and Halilaj, Eni and Black, Michael J.}, booktitle = {IEEE/CVF Conf.~on Computer Vision and Pattern Recognition (CVPR)},month = jun, year = {2024}, doi = {}, month_numeric = {6},
}